The GMC - A Regulator Afraid of Transparency?
Over the last week it has become apparent that the General Medical Council (GMC) - the UK PSA Regulator for Doctors1 - has been systematically hiding content publish on its website relating to PAs and AAs from Search Engines and blocking The Internet Archive from archiving snapshots of their website.
While there is certainly considerable controversy about the role of PAs & AAs, the decision for the GMC to become their regulator, and scope of practice this post is singly about the behaviour and actions of the GMC. It is unfortunately the case that the lack of transparency and candour being demonstrated relates to information on PAs and AAs.
- An Accidental Discovery
- Asking the GMC
- A Damning Further Discovery
- Is This Intentional?
- Freedom of Information Requests
An Accidental Discovery
I initially discovered that something was wrong on Monday the 16th of September 2024 when I attempted to archive the this page on the GMC website providing information on the future process of revalidation for PAs and AAs and encountered the following:
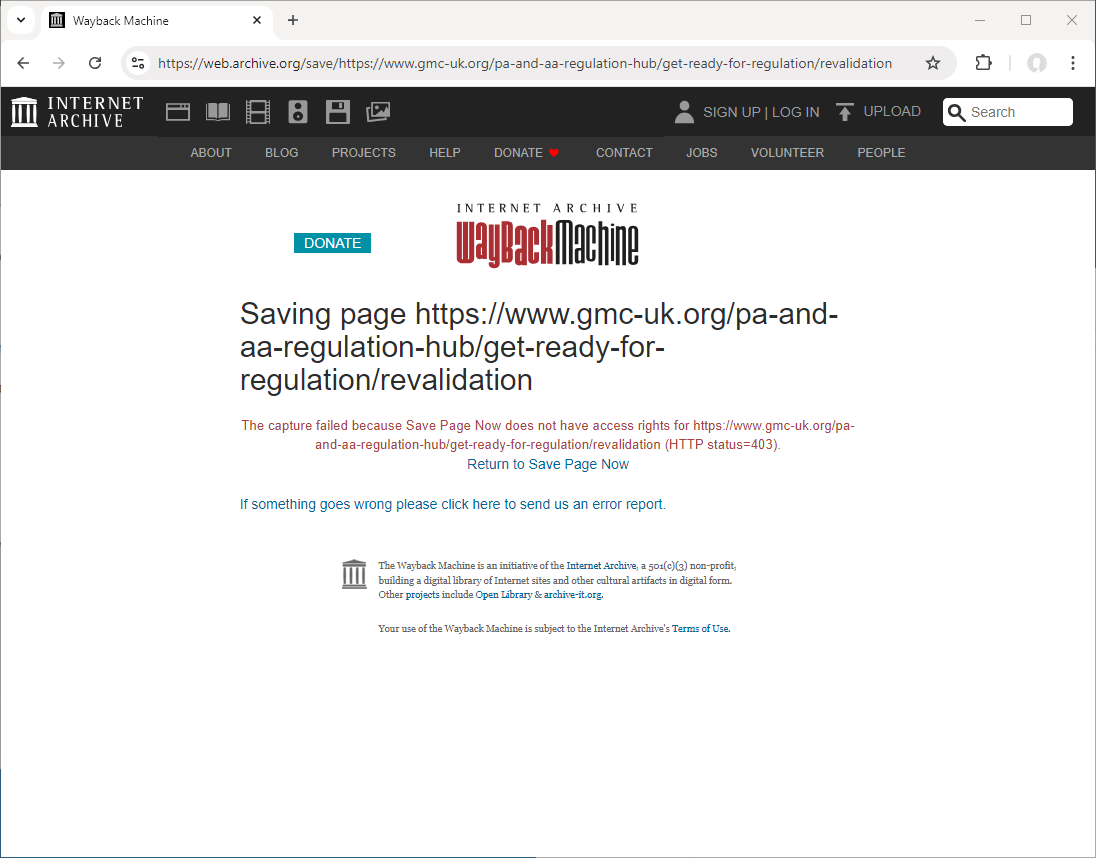
Now there are a number of reasons why the archive.org crawler might be blocked from accessing a website so this error alone shouldn’t be taken as evidence of a deliberate systematic attempt to prevent archiving of pages.
If we look at the homepage of the GMC website and scroll back to 2022 in the Internet Archive we can see that crawlers start to encounter 4xx errors (denoted by the orange colour coding on the calendar view) on the 24th of September 20222. These appear to be successful captures of the page but if you view the archived copy it is an error message from Cloudflare:
Sorry, you have been blocked
You are unable to access gmc-uk.org
This blocking only impacts specific archivists/ bots (that majority of which appear to be run directly by the Internet Archive directly or on behalf of clients/ institutions)3 while permitting others e.g Common Crawl, GDELT Project (that are independent of the Internet Archive) to continue to preserve snapshots. This pattern is repeated across the whole GMC website not just the home page.
It is worth explaining that while the Internet Archive appears to be one single service is actually hosts captured pages from multiple different archivists (and their bots) not just pages saved by their own crawler (archive.org_bot).
Asking the GMC
As seems to be only way to get a response from the GMC I took to Twitter to ask them about this (and bring lots of eyeballs to their behaviour):
Hey @gmcuk why are you blocking @internetarchive from saving pages on your website? This seems to be fairly intentional not a "configuration issue". Why don't you want a historic record of things you published to exist?

After picking this up at ~10am the GMC social media team allegedly looked into this with their IT department to come up with the following response:
Replying to @gmcuk, @blu3id and @internetarchive GMC@gmcukHi Mike. We've checked on this with our IT team. There isn't anything in our systems that's preventing information from our website to be archived. We'll contact the archive website to report this. Thank you.


The error in my original complaint clearly shows that the Internet Archive Save Page Now crawler received a HTTP 403 Forbidden error demonstrating that the issue is not with the Internet Archive but the GMC web server or likely in this case the CDN(Cloudflare) configured by the GMC IT team to protect it.
Therefore this response demonstrates one or a combination of the following:
Lack of competence from the GMC IT team
Demonstrated by the seeming inability to understand the basics of how the internet works and common error codes (403) and their meaning, not to mention how they have configured the GMC website infrastructure.
Failure to consult / adequately communicate with IT by the social media team
It is possible the social media team didn’t share the Tweet and/or attached screen capture showing the error information to the IT team and so got an inadequate response. They may also have not asked the IT team and constructed a response themselves. Some other communication failure may also have occurred.
Wilful obfuscation of an established policy and technical countermeasures to enforce it
It is possible that someone in the chain of responding to this query wilfully decided to obscure a policy to block the Internet Archive crawlers. Or the policy to block the crawlers is only known to a few individuals e.g Cloudflare configuration was updated but not widely documented or shared with the whole IT team.
A Damning Further Discovery
Engaging in the discussion on Twitter surrounding my initial public question led me to more closely analyse the page that had initially been blocked and led to the discovery of a subtle difference in the raw HTML source code compared to other similar pages on the GMC website.
This page (and the other pages in the same section on PA and AA regulation) carried an additional meta tag: <meta name="robots" content="noindex"> this extra bit of code tells internet search engines that the page must not be indexed and prevents it showing in search results on e.g Google.
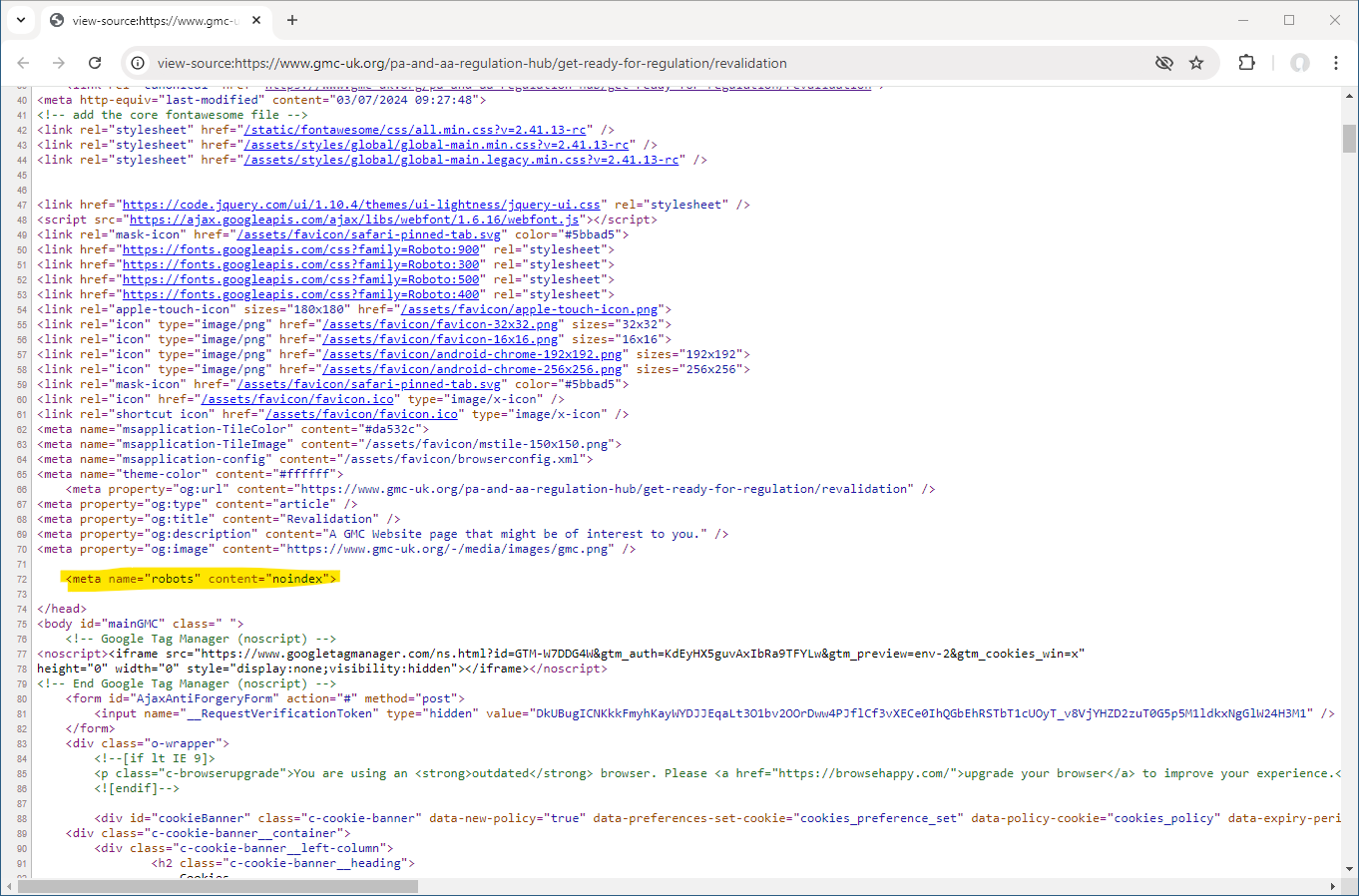
<meta name="robots" content="noindex"> tagThe concerning thing is that this extra instruction to hide pages from search results appears to be limited to pages on PAs and AAs. Looking at a similar page on revalidation but for Doctors we find the following source code that lacks the extra meta tag.
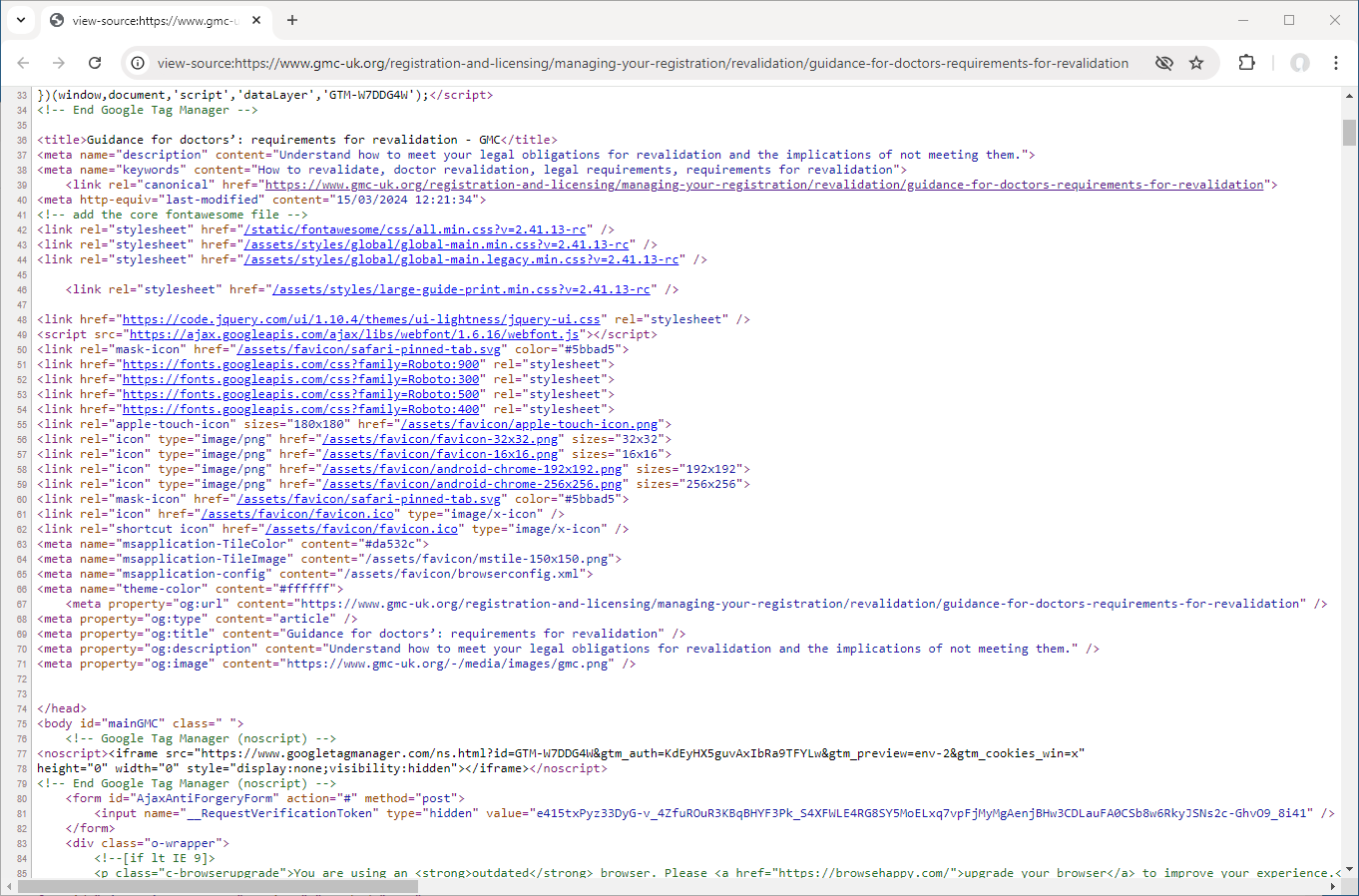
Now while using the <meta name="robots" content="noindex"> is an established method of excluding pages from search results it presents an issue if you are trying to discover which pages on a website have been excluded. The only method is to manually examine pages. The more usual method is to use a robots.txt file but if we examine the GMCs we find the following which is unhelpful in determining if only PA and AA pages are being excluded:
1
2
3
4
5
6
User-agent: *
Allow: /
Sitemap: https://www.gmc-uk.org/sitemap_gmc_en.xml
Sitemap: https://www.mpts-uk.org/sitemap_mpts_en.xml
Sitemap: https://gde.gmc-uk.org/sitemap_gde_en.xml
Sitemap: https://edt.gmc-uk.org/sitemap_edt_en.xml
Back on Twitter the community had also been investigating and found that a News article entitled “More information on PAs and AAs” from October 2023 also has the noindex tag:
This has been going on since at least 2023 and only on specific webpages regarding the regulation of associates.
I tried archiving a @gmcuk webpage in October 23 and couldn't. I saved it instead, and have gone back to look at the coding that @blu3id highlighted. Lo and behold:

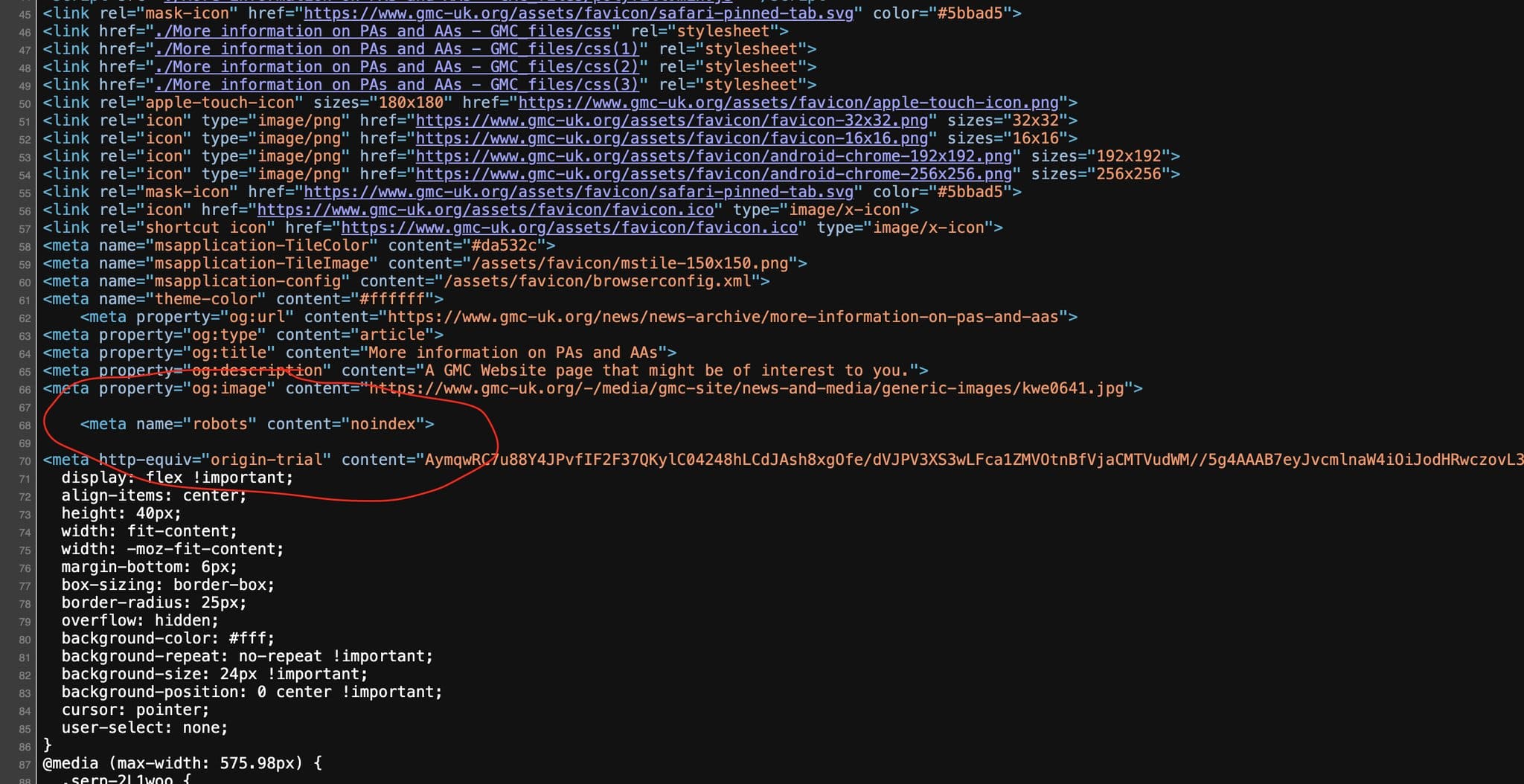
Scrolling back through articles in the GMC News Archive it appears that this page has since been unlisted and is only accessible via a direct link. Reviewing the listed pages in the archive the following also had noindex added:
- GMC responds to NHS England’s update on the Long Term Workforce Plan likely trying to prevent the accompanying letter from being indexed.
Is This Intentional?
It is not possible to be certain with the evidence currently available but there are two questions to be considered:
- Is the GMC explicitly hiding specific PA and AA related content so it doesn’t appear in search results
- Is the GMC attempting to restrict the Internet Archive from preserving the historic state of their website.
Hiding specific PA and AA related content so it doesn’t appear in search results
Considering what has been set out above it is difficult to come up with a logical explanation for why specific pages on the GMC website have the additional <meta name="robots" content="noindex"> tag. Particularly when the only known pages all seem to mention PAs or AAs.
The only explanation I can construct to follow Hanlon’s razor is that the GMC don’t want out-of-date and rapidly changing information on PAs and AAs to end up in search results/ snippets leading to confusion of the general public4. However, this explanation doesn’t account for either:
The fact that search engines frequently re-crawl / index pages as the are updated. That the GMC acknowledge this fact as they have specifically hinted with the
changefreqdirective via the Sitemap in theirrobots.txtthat search engines should consider content on their website to be updated daily and to be re-indexed as such as seen in this snippet:1 2 3 4 5 6
<url> <loc>https://www.gmc-uk.org/pa-and-aa-regulation-hub</loc> <lastmod>2024-09-17T09:41:33+00:00</lastmod> <changefreq>daily</changefreq> <priority>0.5</priority> </url>
That the two “News” articles we know of mentioning PAs/AAs (“More information on PAs and AAs” & “GMC responds to NHS England’s update on the Long Term Workforce Plan” with its accompanying letter) don’t contain content that would be updated in the same way as details of revalidation and quality assurance of PAs and AAs might conceivably change.
Given the above on the balance of probabilities it is very likely that there is a policy to explicitly hide specific PA and AA related content so it doesn’t appear in search results. It is unclear what the justification of this might be but the Hanlon’s razor explanation doesn’t appear to hold water.
Restricting the Internet Archive from preserving the historic state of the GMC website
It is much harder to conclude even on the balance of probabilities on whether or not the GMC is employing technical countermeasures to intentionally restrict the Internet Archive from preserving their website as the available information is mostly circumstantial.
Alongside what has already been outlined regarding the inconsistent blocking of archivists/ bots it is also worth considering the following:
Cloudflare with its default configuration when protecting a website will not routinely block the Internet Archive bot
archive.org_botor e.ggooglebotGoogle’s search indexing bot as they are “Verified Bots”. They also provide clear documentation outlining how more custom configuration may inadvertently block bots and how to ensure that known/verified bots are excluded.Using two tools provided by Google (Rich Results Test and AMP Test) alongside their primary purpose they also enable you to determine if
googlebotis blocked from accessing a website. The GMC website and the specific page that was blocked are accessible with these tools.The majority of the public GMC website is static content that is easy and cost effective to serve to the internet i.e there is limited to no reason to block bots/crawlers from accessing it. The GMC register is the only exception to this as they provide this as a commercial product. However it is segregated to paths under
https://www.gmc-uk.org/doctorsso limiting Cloudflare rules to combat bots and scrapping to this path would be how a competent IT professional would configure the service.
To summarise what we know: From at least the 24th of September 2022 onwards a number of Internet Archive operated bots including their Save Page Now tool have been blocked from archiving the GMC website instead capturing an error message from Cloudflare. Google (and their bot googlebot) don’t appear to have been impacted. Third party archivists including Common Crawl (CCBot) and The GDELT Project that contribute to the Internet Archive also don’t appear to have been impacted.
Considering Hanlon’s razor we could assume that the GMC IT team want to block bots from scraping the medical register - both for commercial reasons and potentially the performance impact on their servers due to the likely dynamic nature of those pages. Given what we know about Cloudflare’s bot protection settings and verified bots it is likely that a specific custom configuration was used to increase the bot protection vs. default settings. However again this doesn’t account for:
That custom settings to restrict bots from the Pro plan upwards all ask you to configure how you want to handle verified bots. For the Enterprise product it is not as straightforward but there is good documentation and you are paying enough that you get support from a “Customer Success Manager” to help you implement this.
That some but not all verified bots e.g Google’s
googlebotand Common CrawlCCBotare not blocked but The Internet Archivesarchive.org_botis. This seems to indicate that the choice to simply permit verified bots when configuring bot protection wasn’t made and something more custom was created and specific bots were either permitted or blocked.
In coming to a conclusion it is also worth noting that through further investigation it appears that the Internet Archive’s Save Page Now tool doesn’t present itself as archive.org_bot when taking snapshots of a website. This means that it is entirely possible that Cloudflare may block this in default configurations where verified bots are permitted. However while this may explain the issue that started this all it doesn’t account for the blocking of other Internet Archive bots3 which do present themselves as archive.org_bot.
Given the inconsistencies in creating an alternative explanation it seems more plausible that there is a specific (although partially ineffective) attempt to restrict the Internet Archive from preserving the historic state of the GMC website. It may be that this is an unintentional side-effect to protect the medical register from scraping - but no consistent explanation currently supports this. The GMC social media team also don’t put the organisation (or the IT Team) in a good light when we consider their response.
Freedom of Information Requests
One way of shining more light on this and getting a hopefully more logical response from the GMC than that provided by their social media team is to use Freedom of Information Act 2000 to compel a response. However, it is well know that organisations routinely mislead in responses, interpret requests narrowly to avoid disclosure, or attempt to apply exceptions to requests.
Therefore, carefully constructed and specific requests need to be formulated to elicit the following:
- A list of the current pages on the gmc-uk.org website including their URLs that have the
<meta name="robots" content="noindex">tag - A list of the historic pages on the gmc-uk.org website including their URLs (or content if no longer accessible) that had the
<meta name="robots" content="noindex">tag at some point - The supplier of the content management system used to manage the GMC website
- The name of the content management system/software
- Determine the cost of implementing the feature to add the
<meta name="robots" content="noindex">tag - When this feature was added
- When a request to first enable or use this functionality was made
- Any policy or document outlining which pages should routinely have this applied
- Any emails/minutes/correspondence discussing blocking search engine indexing
- Configuration of Cloudflare bot protection - explicitly whitelisted bots, explicitly banned bots
- Dates of Cloudflare configuration changes for the last 24 months
- Type of Cloudflare subscription/service purchased by GMC
- When Cloudflare was adopted by the GMC/ their suppliers
- Any emails/minutes/correspondence discussing blocking archiving of the GMC website
I will try to submit these requests myself and will update this page as new information becomes available. If you have already submitted requests and receive something that you think is relevant please get in contact and I will add it to this page. Any feedback, comments, criticism, correction or suggestions on what is have outlined are also much appreciated.
Subscribe to get future posts by email (or use the RSS feed)
The GMC will also soon regulate the misleadingly named: Physician Associates (née Physician Assistants) and Anaesthesia Associates (née Physician Assistants (Anaesthesia)) ↩
Yes if you continue to scroll back to 2021 there is a 4xx error on the 27th of February but this appears to be much more likely either a genuine server error or misconfiguration by the crawler. ↩
The impacted archivists/ bots included:
- ArchiveBot -
ArchiveBotis one of the crawlers operated by Archive Team a group dedicated to digital preservation and web archiving. - Save Page Now - The Internet Archives own tool to save a page now
- Save Page Now Outlinks - A bot that is part of the Internet Archive’s Save Page Now tool that archives linked pages from those added
- Archive-It - The subscription web archiving service of the Internet Archive
- The Public Record Office of Northern Ireland (PRONI) - As a client of Archive-It
- Sexual and Gender Minority Health web archive - A selective collection of web resources archived by the National Library of Medicine beginning in 2024 related to Sexual and Gender Minority health as a client of Archive-It
- National Library of Medicine - As a client of Archive-It
- Certificate Transparency
- LAC Domain Harvest 2024 - An archive crawl performed by Internet Archive on behalf of the Library and Archives Canada in January-March, 2024
- Custom Crawl Services - Large-scale web harvests and national domain crawls performed for National Libraries by the Internet Archive
- Save Page Now - Cloudflare - A bot that is part of the Internet Archive’s Save Page Now tool
- ArchiveBot -
Confusion that is that is greater than the misleading language of associate vs. assistant, or medical professional. See the current legal challenge of the GMC being organised by Anaesthetists United. ↩
- Published
- Last Update
Update History 3152
- Fix image paths
- The GMC - A Regulator Afraid of Transparency